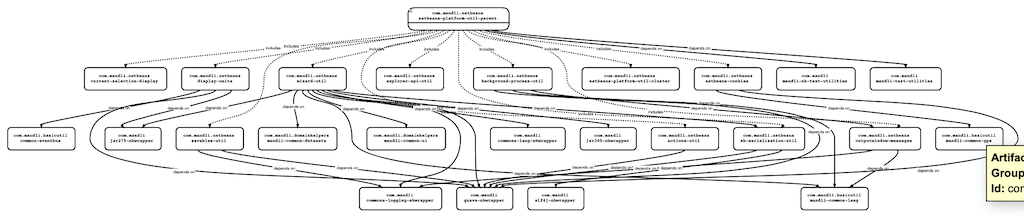
Throughout the years, I have seen short programs exporting dependencies from POM files into visual diagrams. A few of them are in 3D and it looks pretty cool… but it is not very helpful. Most of the projects I have worked on have too many dependencies to be viewable in a diagram format. Lately, I have written a short program to export those dependencies and modules in a csv format importable by draw.io. I added filters to remove dependencies that are not useful. This post is about how I had to deal with the draw.io format to accomplish that task.
The official documentation is here: https://about.draw.io/automatically-create-draw-io-diagrams-from-csv-files/
Draw.io provides a template with instructions that you can find under Arrange -> Insert -> CSV:

You can change the info you want to display as well as the styles of the boxes and arrows. You can find examples here: https://about.draw.io/import-from-csv-to-drawio/
First trick: To figure out what style what I wanted, I used draw.io’s UI to set it up usng “edit style” and copied/pasted the style in the csv content.
## Node style (placeholders are replaced once). ## Default is the current style for nodes. # # style: label;whiteSpace=wrap;html=1;rounded=1;fontStyle=0;spacingLeft=0;strokeWidth=1;align=center;%ExtraStyle% #
Second trick: Simple one, but very useful: one csv line = one block! To create connections, you need at least two columns: your data ID and the referent data ID. However, having a referent ID does not create a block. If it does not exist, Draw.io will ignore it.
Third trick: Connections! the csv format is not well designed to handle nuumerous one to many/many to many relations. Remember the second trick: one line = one block. if you have:
id 1, connection 1 id 1, connection 2 id 1, connection 3
Draw IO will display three id 1 blocks having each their connection. Instead, what is needed is:
id 1, connection 1, connection 2, connection 3...
This implies that you create as many connection configurations as connections you need.
# connect: {"from": "id 1", "to": "connection 1", "invert": true, "label": "depends on", \
# "style": "curved=1;endArrow=blockThin;endFill=1;fontSize=11;"}
# connect: {"from": "id 1", "to": "connection 2", "invert": true, "label": "depends on", \
# "style": "curved=1;endArrow=blockThin;endFill=1;fontSize=11;"}
# connect: {"from": "id 1", "to": "connection 3", "invert": true, "label": "depends on", \
# "style": "curved=1;endArrow=blockThin;endFill=1;fontSize=11;"}
etc.
And this can look tedious, but it is very easy to do programmatically.
for (i in 1..maxNumDependencies) {
destinationFile.appendText(
"# connect: {\"from\": \"DependencyId$i\", \"to\": \"Id\", \"invert\": false, \"label\": \"depends on\", \\\n" +
"# \"style\": \"curved=1;endArrow=blockThin;endFill=1;fontSize=11;\"}\n"
)
}
All the rows need to have the same number of columns as the csv header row. Otherwise, the import will be fail:

I was able to import more than 100 dependencies without problem. The only issue is not so much the import, but how to present so many connections in a diagram. It is unreadable!
Last trick: another simple and trivial: make sure there is no empty line. You can waste much time trying to figure this out since the error message does not say much (same as previous one).
My code inserted a empty line before listing the connections:
Connections between rows ("from": source colum, "to": target column).
Label, style and invert are optional. Defaults are '', current style and false.
In addition to label, an optional fromlabel and tolabel can be used to name the column
that contains the text for the label in the edges source or target (invert ignored).
The label is concatenated in the form fromlabel + label + tolabel if all are defined.
The target column may contain a comma-separated list of values.
Multiple connect entries are allowed.
#
connect: {"from": "ModuleId1", "to": "Id", "invert": false, "label": "includes", \
"style": "curved=1;endArrow=blockThin;endFill=1;fontSize=11;dashed=1"}
And I wasted a few minutes to figure out why the import did not work… But now, you know!
